[智能风控]集成模型评分卡02
- 4 mins信用评分卡的计算
信用评分卡使用比例缩放的评分映射方法。例子:首先期望用户的基础分为650,当非逾期比例的概率是逾期比例的概率2倍时,加50分;当非逾期比例的概率是逾期比例的概率4倍时,加100分。换算成标准评分卡公式为
逻辑回归的评分卡映射
对于逻辑回归来说,。对应其输出$y=\ln(\frac{P_{正样本}}{P_{负样本}})$。故可求得 。 这样只要计算出每个特征的逻辑回归系数,就你能够计算出当前客户的标准化信用评分。650相当于基础,50相当于斜率,用于调节信用分的值域。
xgboost的评分卡映射
对于树模型,输出的概率是负样本(即标签为1的概率),故1-pred就为正样本的概率。其评分映射公式为 其中lag为基础分似然概率阈值,也可以不设置。
模型训练
xgboost+LR
模型的目的是为了什么?
一个根据每个人特征,可以给一个相对的模型评分,这个模型的输入还是用户的基本属性、行为信息、财务状况等,模型的标签为是否逾期。即1为负样本,0为正样本。通过计算出每个用户的评分,可以对于客群进行授信、推荐或者其他消费金融任务。
模型训练的具体细节放在代码里,细节只有一个对于不平衡样本的处理,可以在逻辑回归中使用class_weight=‘balanced’和xgb中使用scale_pos_weight 进行调节。
训练之后集成可以使用bagging直接进行集成,推荐使用xgb+rf+lr多方面进行集成,这样既能降低模型方差又能降低偏差。
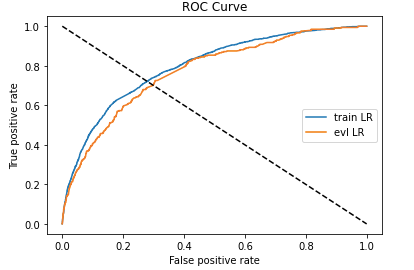
ROC曲线和KS值评估
模型的评估从两个方面进行考虑,一个是模型的分类区分度,一个是模型的对客户进行正确排序的能力。
首先生成模型报告: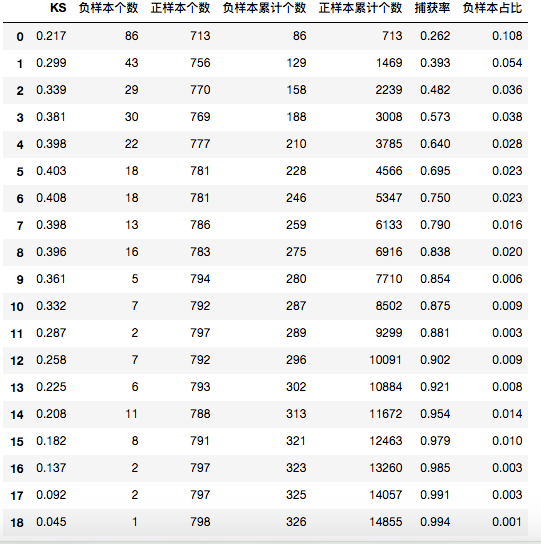
可以看到模型报告关注几个方面:KS值即分箱之后每个箱的区分能力,可以看到,以分类概率降序分箱,其负样本的占比应该是从高到低的,这样复合每个分箱的模型稳定性。捕获率可以看出前五箱就捕获了大部分的负样本,这样在授信或者其他任务中,只要拒绝掉分数20%的人,就可以捕获到超过一半的负样本。
pyechart可视化
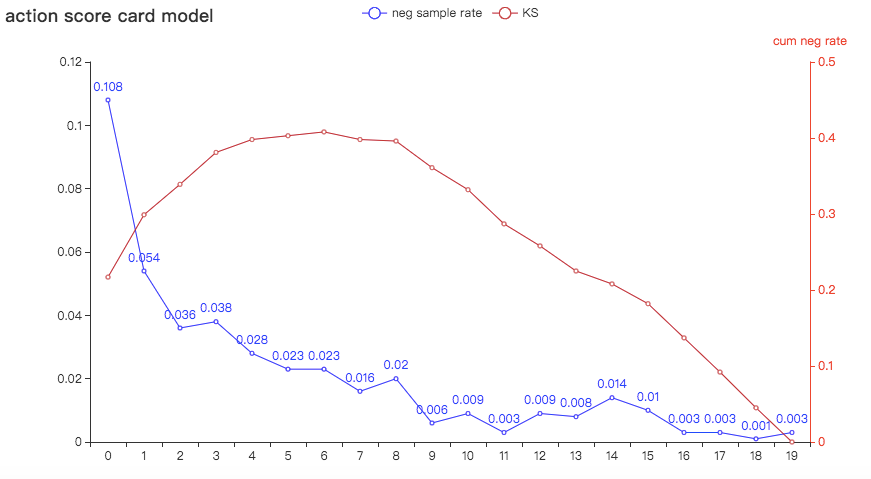
可以看到除了负样本占比在第四箱的时候略微波动,其他时间都相对稳定,排序能力可以接受。
同样,评分映射,也可以看到不会影响模型的排序能力,以此来验证模型的评分逻辑是否正确。
#计算分数
def score(person_info,finance_info,credit_info,act_info):
xbeta = person_info * (3.4946237)\
+ finance_info * (11.40440098) \
+ credit_info *(2.45601882)\
+ act_info * (-1.6844742)
score = 650 - 34 * (xbeta)/math.log(2)
return score
val['score'] = val.apply(
lambda x :score(x.person_info,x.finance_info,x.credit_info,x.act_info),axis=1)
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_score)
val_ks = abs(fpr_lr-tpr_lr).max()
print('val_ks',val_ks)
评估函数优化
对于xgb来说,有两个重要的参数可以进行优化,xgboost.train中有两个重要参数: obj和feval。obj为目标函数,feval为评估函数。
首先对于目标函数,在xgb中为损失函数,衡量的是拟合程度。
如何让损失函数最小?如何让模型拟合的好?
首先,损失函数是不是越小越好? 不是,因为对于损失函数是有期望的,即风险函数。风险函数包括两个方面,经验风险是训练集的平均损失,我们的目标首先要最小化经验风险。除此之外,为了防止过度学习历史数据,真实预测时候不好,我们加入结构风险,用于度量模型的复杂度。
对于每个分类算法,就会有对错,错了就有代价,代价就是损失,分类的目标函数就是要代价最小。所以,对于分类算法来说,目标函数就是代价函数,或者叫做损失函数。
在对于目标函数的优化中,我们主要考虑这两个方便,一个是经验风险拟合程度,一个是结构风险。这可能涉及到不平衡样本,focal loss或者各种正则化,或者树模型中加入叶子节点的数量等,从模型方面优化目标函数。
同样对于评估函数,则可以考虑多个业务含义。我需要前百分之20的样本比例更大,或者证券中我需要某些行业的更关注,这些对于业务指导是有含义的?
附上官方的定义文档
# user define objective function, given prediction, return gradient and second order gradient
# this is log likelihood loss
def logregobj(preds, dtrain):
labels = dtrain.get_label()
preds = 1.0 / (1.0 + np.exp(-preds))
grad = preds - labels
hess = preds * (1.0 - preds)
return grad, hess
# user defined evaluation function, return a pair metric_name, result
# NOTE: when you do customized loss function, the default prediction value is margin
# this may make builtin evaluation metric not function properly
# for example, we are doing logistic loss, the prediction is score before logistic transformation
# the builtin evaluation error assumes input is after logistic transformation
# Take this in mind when you use the customization, and maybe you need write customized evaluation function
def evalerror(preds, dtrain):
labels = dtrain.get_label()
# return a pair metric_name, result. The metric name must not contain a colon (:) or a space
# since preds are margin(before logistic transformation, cutoff at 0)
return 'my-error', float(sum(labels != (preds > 0.0))) / len(labels)
# training with customized objective, we can also do step by step training
# simply look at xgboost.py's implementation of train
bst = xgb.train(param, dtrain, num_round, watchlist, obj=logregobj, feval=evalerror)
xgb的自定义损失函数需要考虑二阶可导。 如果现在有一个提额模型,希望给出分数最大的20%的客户更高的额度,所以希望获取客群找那个正样本(预测比例较低的20%)捕获率最大化,同时,也要保证一部分的正负样本区分能力。
# 自定义损失函数,需要提供损失函数的一阶导和二阶导
def loglikelood(preds, dtrain):
labels = dtrain.get_label()
preds = 1.0 / (1.0 + np.exp(-preds))
grad = preds - labels
hess = preds * (1.0 - preds)
return grad, hess
# 自定义前20%正样本占比最大化评价函数
def binary_error(preds, train_data):
labels = train_data.get_label()
dct = pd.DataFrame({'pred': preds, 'percent': preds, 'labels': labels})
# 取百分位点对应的阈值
key = dct['percent'].quantile(0.2)
# 按照阈值处理成二分类任务
dct['percent'] = dct['percent'].map(lambda x: 1 if x <= key else 0)
# 计算评价函数,权重默认0.5,可以根据情况调整
a = np.mean(dct[dct.percent == 1]['labels'] == 1) * 0.5
result = np.mean(dct[dct.percent == 1]['labels'] == 1) * 0.5 \
+ np.mean((dct.labels - dct.pred) ** 2) * 0.5
return 'error', result